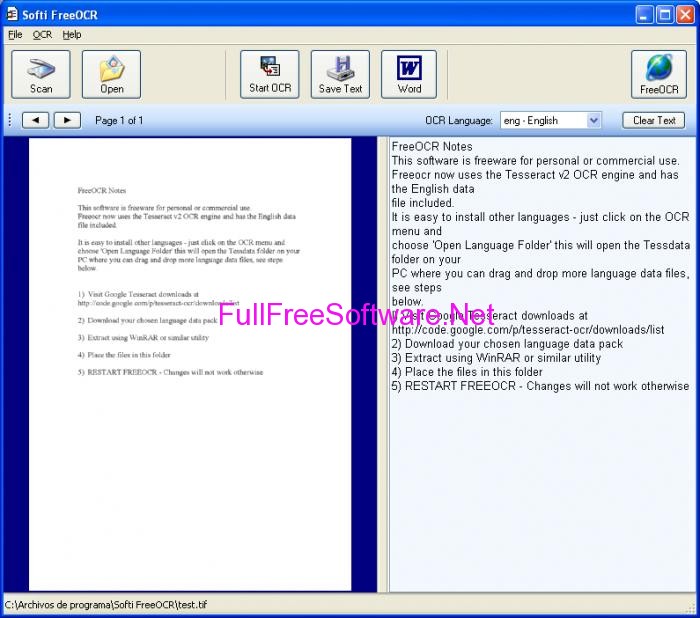
FreeOCR is a tool that can extract text from image files and PDF documents. The application is simple to install and, more importantly, free to use. The user interface is standard, and there are no special features to be found here. You can open an image or PDF file by either using a scanner, or by looking for it in the computer. The content of the source file will be displayed in the first window, and after clicking “OCR”, you will immediately see the result in the second window.
FreeOCR free download
The output text can be edited (which is not necessarily a good thing), and you have to press the small red x to clear screen each time you insert new information. Otherwise, texts will be delimited by a single line break, and if you accidentally click “Remove line break“, you won’t get to use an Undo button.
Output text can be saved as a text file or Word document.
The conversion quality is not so great. We first tried extracting text from a PDF document. Everything was in place, except for special characters found in other languages than English, that weren’t even taken into account (this type of character is replaced by blank).
In the next step, we opened Windows’ Paint, and wrote some text in lowercase and uppercase, as well as symbols. FreeOCR didn’t manage to get it right, at least not all of it. Although it was the same text displayed in lowercase and uppercase, the two results were completely different, and the symbols were not accurate either. System CPU and memory usage is pretty high for such a small software. At least the conversion time is fast, and there are no errors.
In conclusion, if you want to extract text from images and PDFs, then you can at least try FreeOCR. Just make sure to verify results (although it would be faster if you transcribed the whole text yourself). But it’s free.